はじめに
DockerやKubernetesを使ってマイクロサービスなどを構築する時に必要になるネットワークの基礎知識まとめ、その2です。
その1は下記です。
今回のその2では、
- VLAN
- network namespace
- iptables
について記載しています。
VLAN
VLANはネットワーク機器の物理構成に引っ張られず、仮想的にネットワークを分ける仕組みです。ポートVLANとタグVLANの2種類あります。
ポートVLAN
ポートVLANはネットワーク機器の物理ポート(NIC)をグルーピングすることで、一台のマシンで複数種類のネットワークを用意できる技術です。
例えば、L3スイッチはそのままではWANとLANを混在させることができませんが、前半分のポートをWAN用、後ろ半分をLAN用として設定することで、混在させることができます。L2スイッチでは、リモートマシン用とプライベートネットワーク用に分けたりします。
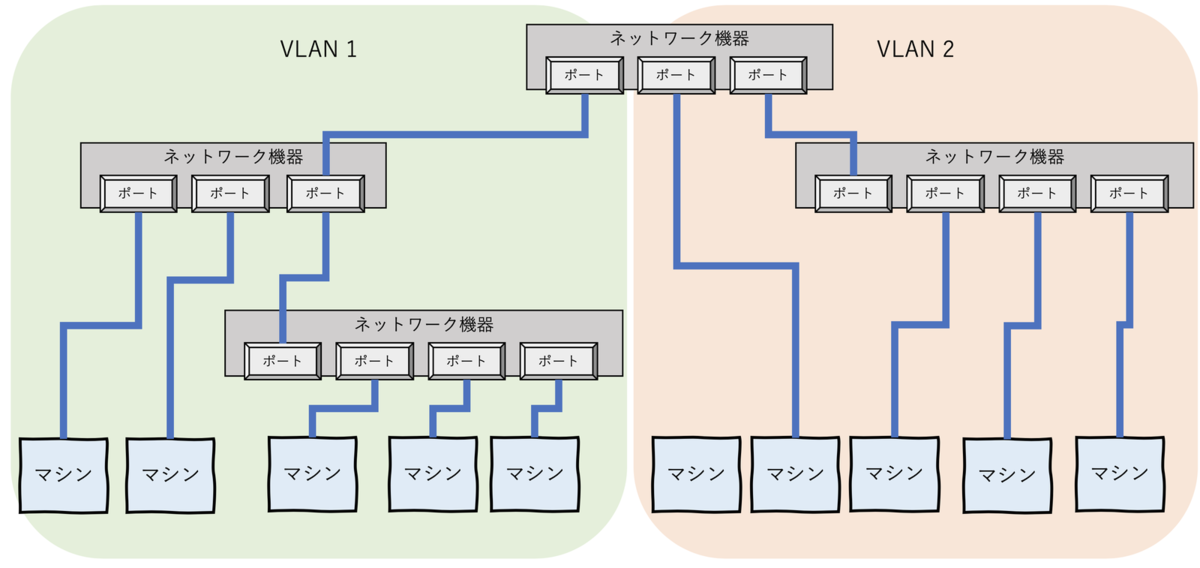
タグVLAN
カスケードによって台数が増えてくると、ポート数が足りなくなってきてしまいます。そういったときはポートでLANを分けるのではなく、タグをつけてVLANを組む方が便利になります。
タグVLANはその名の通り、所属するVLANのIDとなるタグをデータにくっつけて、通信を行う方法です。これにより物理的に離れた機器でも同じVLAN IDが振られていれば、L2スイッチを経由して通信ができるという仕組みです。VLAN IDはEthernetヘッダーに含まれ、転送されます。

VXLAN
Virtual eXtensible Local Area Networkの略です。 VXLANは、送信元側でEhternetフレームをUDP/IPでカプセル化し、宛先まで届ける技術です。
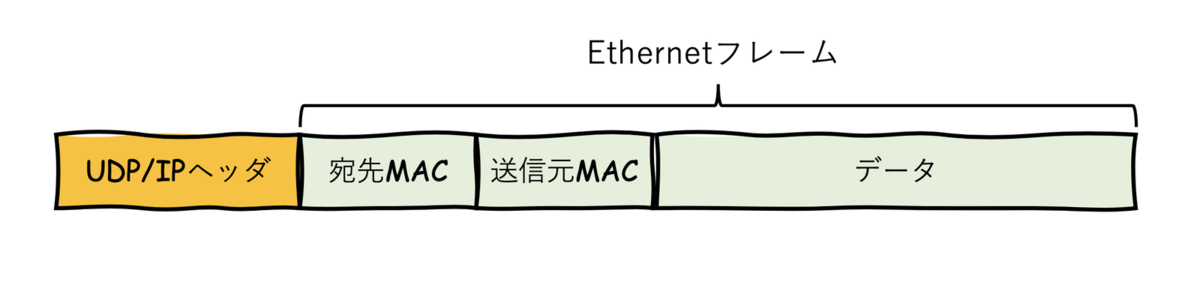
VLANの上位互換という特徴と、ネットワークオーバレイという特徴を持ちます。
- VLANの上位互換
上記の通り、ポートVLANは物理機器のポート数に依存するため、数が限られています。タグVLANもタグとしてつけられるIDが12ビットと規定されているため、最大でも212≒4000のセグメントになってしまい、それ以上の大規模ネットワークには対応できません。 そこでさらに拡張(eXtensible)できるように開発されたものがVXLANとなっています。 VXLANのIDであるVNI(VXLAN Network Identifier)は24ビットであるため、224=約1600万の背エグメントを用意できます。
- ネットワークオーバレイ
UDP/IPでカプセル化するため、途中の経路にあるスイッチやルータから見ると単なるUDP/IPのパケットとして見えるため、通常通り転送されていきます。転送先のネットワークに届くとカプセルが解除され、Ethernetフレームのヘッダに記載のあるマシンに送られます。
通常であれば、スイッチやルータを通ることで、EthernetヘッダやIPヘッダは付け替えられます(つまりMACアドレスやIPアドレスが変わります)が、VXLANによるカプセル化によって、同じEthernetヘッダ、IPヘッダのまま転送先ネットワークに到達させることができます。 この特徴は、仮想マシンのIPアドレスを変えることなく、別ネットワークにマイグレーションしたい場合に効力を発揮できます。通常であれば別ネットワークに移すとIPセグメントが変わるため、マシンのIPアドレスも変えざるを得ませんが、VXLANを使うことでIPを変えずに別ネットワークでも同じIPセグメントを使えます。 マシンのスケール時や、障害対応、災害発生時にマイグレーションしやすくなります。
なお、同じL2セグメントのデータ(Ehternetフレーム)のまま、L3ネットワークを越えて、通信できるため、L3ネットワーク越え=オーバレイと言われています。論理的なL2セグメントを構築できる、とも言われます。
Network Namespace
NetworkNamespaceとは
Linuxのリソース仮想化の1つでnetnsとも書かれます。
通常は、ネットワークインターフェイス(eth0, eth1など)やルーティングテーブル、ソケットなどのネットワークスタックはOS全体で1つ持っています。 これらを分離して互いに影響のないように利用したい場合にnetnsが活躍します。例えば複数のコンテナを1つのマシン上で起動させ、それぞれ処理をさせたい場合に有用になります。各コンテナのnetnsをホストのnetnsや他コンテナのnetnsから分離することで、ホストに影響を与えることなく、コンテナ独自のネットワークをカスタマイズできるからです。 自分でnetnsを作成し、そこに
- ネットワークインターフェース
- ルーティングテーブル
- ファイヤーウォールルール
- ソケット
などを割り当てていくイメージで利用します。
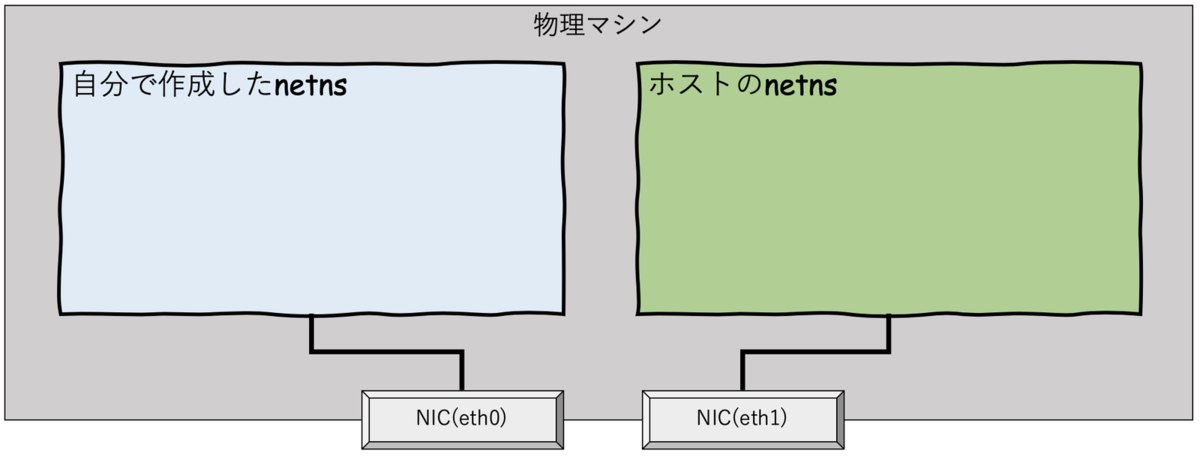
独自netnsと外部とで通信するためには
自分で作成したnetnsを外部と通信するためには、仮想インターフェースvethの仕組みがよく利用されます。
自分で作成したnetnsもホストと同じようにeth0といった物理インターフェース(NIC)に割り当てることでも利用できますが、その場合、ホストのインターフェースは限られているためスケールできません。
vethを使うことでNICの数によらずインターフェースを作成してネットワークを構築することができます。

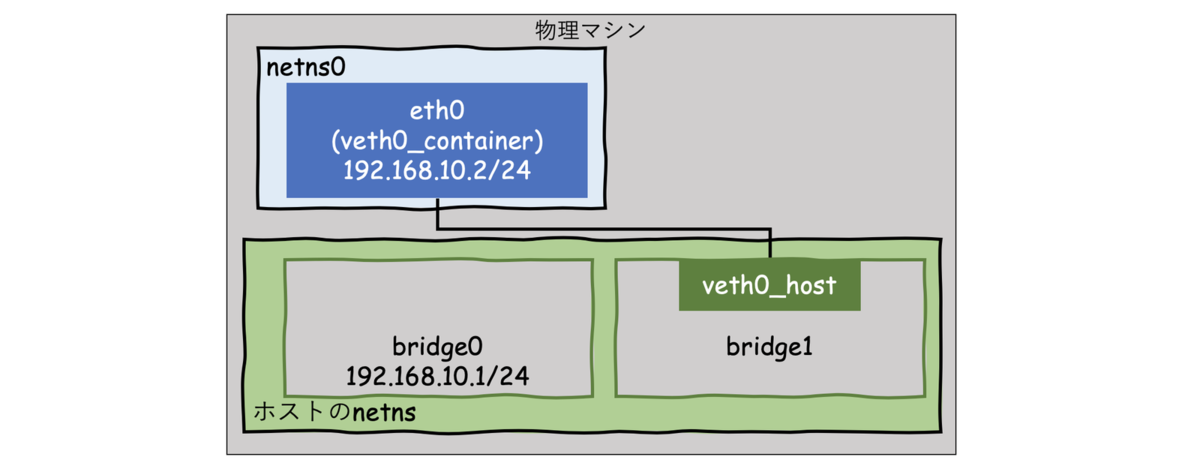
図の仮想bridgeでは、MACアドレスによるルーティングにより、veth間の通信を可能にしています。具体的な仕組みは次のお試しで理解できると思います。
実際にbridgeを作成し、独自ns間の通信を試してみる
お試しの流れは下記です。
- bridgeの作成
- netnsの作成
- vethペアの作成
- それぞれ割り当て
- 通信テスト
下図の状態を作成し、実際にnetns0からbridgeやホストにアクセスできることを確認してみます。

bridgeの作成
図の通りにまずはbridge0を追加します。
$ sudo ip link add name bridge0 type bridge
$ ip link show bridge0
386: bridge0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 06:e6:be:e9:5b:92 brd ff:ff:ff:ff:ff:ff
作成自体はできましたが、IPアドレスがまだ付与されていないため、アクセスができません。ということでbridge0にIPアドレスを追加します。
$ sudo ip addr add 192.168.10.1/24 broadcast 192.168.1o.255 label bridge0 dev bridge0
$ sudo ip addr show bridge0
386: bridge0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 06:e6:be:e9:5b:92 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.1/24 brd 192.168.10.255 scope global bridge0
valid_lft forever preferred_lft forever
IPアドレスが設定通りに追加されたことがわかります。
ただし状態としてはまだ DOWNになっているため、このままでは使えません。使える状態へとリンクアップする必要があります。
$ sudo ip link set dev bridge0 up
infra@quanta02:~$ sudo ip addr show bridge0
386: bridge0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 06:e6:be:e9:5b:92 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.1/24 brd 192.168.10.255 scope global bridge0
valid_lft forever preferred_lft forever
inet6 fe80::4e6:beff:fee9:5b92/64 scope link
valid_lft forever preferred_lft forever
状態がUPに変わっています。
netnsの作成
bridgeを作成したあとは、ip netnsコマンドでnetnsを作成します。名前はnetns0にします。
$ sudo ip netns add netns0
$ ip netns show
netns0
vethペアの作成
vethのペア(veth0_host, veth0_container)を作成します。
$ sudo up link add veth0_host type veth peer name veth0_container
$ sudo ip link show veth0_container
387: veth0_container@veth0_host: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether de:c6:09:9e:2b:cf brd ff:ff:ff:ff:ff:ff
$ sudo ip link show veth0_host
388: veth0_host@veth0_container: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether a2:01:d8:45:5b:40 brd ff:ff:ff:ff:ff:ff
bridge0にveth0_hostを割り当て
作成したペアのうち、veth_hostをbridge0で利用する設定を実行し、リンクアップさせます。
$ sudo ip link set dev veth0_host master bridge0
$ sudo ip link set dev veth0_host up
$ sudo ip link show veth0_host
388: veth0_host@veth0_container: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue master bridge0 state LOWERLAYERDOWN mode DEFAULT group default qlen 1000
link/ether a2:01:d8:45:5b:40 brd ff:ff:ff:ff:ff:ff
master bridge0という設定が増えていることがわかります。
netns0にveth0_containerを割り当て
ホスト以外の別のnetnsに設定を適用したり、設定を確認するには、ip netns exec netns0の後に実行したいコマンドを入力します。こうすることで、指定したネットワーク空間でコマンドが実行されます。
例えば、作成したnetns0内の設定を確認するには下記を実行することで、表示されます。
$ sudo ip netns exec netns0 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
最初はloopbackの設定のみが存在しています。
ちょっと寄り道実験: 上記をみると、netnsを作成したばかりの段階では、loopbackアドレスすらDOWN状態になっています。そのためpingしても通りません。
$ sudo ip netns exec netns0 ping localhost
PING localhost (127.0.0.1) 56(84) bytes of data.
^C
--- localhost ping statistics ---
78 packets transmitted, 0 received, 100% packet loss, time 78850ms
これをリンクアップしてみると、pingが通るようになります。
$ sudo ip netns exec netns0 ip link set dev lo up
$ sudo ip netns exec netns0 ping localhost
PING localhost(localhost (::1)) 56 data bytes
64 bytes from localhost (::1): icmp_seq=1 ttl=64 time=0.033 ms
64 bytes from localhost (::1): icmp_seq=2 ttl=64 time=0.022 ms
64 bytes from localhost (::1): icmp_seq=3 ttl=64 time=0.026 ms
^C
--- localhost ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2053ms
rtt min/avg/max/mdev = 0.022/0.027/0.033/0.004 ms
さてnetns0での設定方法がわかったところで、vethペアのもう片方であるveth0_containerをnetns0へ移動させます。
$ sudo ip link set dev veth0_container netns netns0
確認してみます。
$ sudo ip netns exec netns0 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noqueue state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
387: veth0_container@if388: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether de:c6:09:9e:2b:cf brd ff:ff:ff:ff:ff:ff link-netnsid 0
確かに移動したことが分かります。
netns0内ではこのveth0_containerを通常のインターフェースとして扱えるようにしたいため、名前を変えておきます。
$ sudo ip netns exec netns0 ip link set dev veth0_container name eth0
$ sudo ip netns exec netns0 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noqueue state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
387: eth0@if388: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether de:c6:09:9e:2b:cf brd ff:ff:ff:ff:ff:ff link-netnsid 0
IPアドレスとデフォルトゲートウェイの設定
実際に通信できるようにnetns0のeth0にIPアドレスを設定します。
$ sudo ip netns exec netns0 ip addr add 192.168.10.2/24 dev eth0
$ sudo ip netns exec netns0 ip link set dev eth0 up
$ sudo ip netns exec netns0 ip addr show eth0
387: eth0@if388: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether de:c6:09:9e:2b:cf brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.10.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::dcc6:9ff:fe9e:2bcf/64 scope link
valid_lft forever preferred_lft forever
続いて、デフォルトゲートウェイも用意します。
$ sudo ip netns exec netns0 ip route
192.168.10.0/24 dev eth0 proto kernel scope link src 192.168.10.2
$ sudo ip netns exec netns0 ip route add default via 192.168.10.1
$ sudo ip netns exec netns0 ip route
default via 192.168.10.1 dev eth0
192.168.10.0/24 dev eth0 proto kernel scope link src 192.168.10.2
設定前後でルーティングテーブルが変わっていることが分かります。
通信テスト
これで一通りの設定は完了です。 実際にnetns0からbridge0にpingが飛ぶかを確認してみます。
$ sudo ip netns exec netns0 ping 192.168.10.1
PING 192.168.10.1 (192.168.10.1) 56(84) bytes of data.
64 bytes from 192.168.10.1: icmp_seq=1 ttl=64 time=0.078 ms
64 bytes from 192.168.10.1: icmp_seq=2 ttl=64 time=0.037 ms
64 bytes from 192.168.10.1: icmp_seq=3 ttl=64 time=0.037 ms
^C
--- 192.168.10.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2038ms
rtt min/avg/max/mdev = 0.037/0.050/0.078/0.021 ms
問題なく接続できました。
さらなる実験として、veth0_hostをbridge0から新たに作成したbridge1に付け替えることで、pingが通らなくなることが確認できます。本設定が必要であることがわかるかと思います。
$ sudo ip link add name bridge1 type bridge
$ sudo ip link set dev veth0_host master bridge1
$ sudo ip link show veth0_host
388: veth0_host@if387: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master bridge1 state UP mode DEFAULT group default qlen 1000
link/ether a2:01:d8:45:5b:40 brd ff:ff:ff:ff:ff:ff link-netnsid 5
$ sudo ip netns exec netns0 ping 192.168.10.1
PING 192.168.10.1 (192.168.10.1) 56(84) bytes of data.
^C
--- 192.168.10.1 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2038ms
これで、1つの物理マシン内での通信ができるようになりました。
今までの設定は、下記のコマンドで全て削除できます。
$ sudo ip netns del netns0
$ sudo ip link del dev bridge0
$ sudo ip link del dev bridge1
一方、他の物理マシンと通信する場合、つまり、物理NICを通って外部と通信する場合には、NATを有効にする必要があります。NATは次で説明するiptablesを使うことで実現できます。
iptables
iptablesにはファイアウォールとルータの機能を備えています。
ファイアウォールは一般的に下記2つに大別できます。
- パケットフィルタリング:ルールベースで通す/通さない通信を設定する
- プロキシ応答:プロキシが外部と内部の間に入り、通信を仲介する
iptablesはパケットフィルタリングに分類されます。 ファイアウォールの種類詳細については、下記が参考になります。
設定コマンドの書式は下記です。
iptables <-t テーブル> <コマンド> <チェイン> <パラメタ> <ターゲット>
書式にある通り、iptablesにはテーブルとチェインという仕組みを使って機能を実現しています。
テーブルは、フィルタリングかルーティングかを設定する項目です。
- filter:パケットフィルタリングのためのテーブル
- nat:NATやIPマスカレード(ポート番号の変換)といったルーティングのためのテーブル
チェインは、”どこを通るパケットか”を設定する項目です。 パケットフィルタリングでは、
- INPUT:入ってくるパケットをフィルタリング
- OUTPUT:出ていくパケットをフィルタリング
- FORWARD:中継するパケットをフィルタリング
の3つを利用します。
ルーティングでは、
の2つを利用します。
各種チェインのイメージが下図です。

図にある通り、PREROUTINGが先に実行され、INPUTやOUTPUT、FORWARDが適用されるため、NAT変換されたあとのIPアドレスやポートの情報を使ってINPUTなどのフィルタリングの設定をする必要があり、注意が必要です。
また、ユーザーが自分でチェインを定義することもできます。DockerやKubernetesでは独自のチェインを定義して、ネットワーク設定が実装されています。
さらなる詳細や具体的な設定方法は下記が参考になります。
おわりに
その2では、VLAN、network namespace、iptablesについてまとめました。 どれも奥が深い技術なので、しっかりと理解したい場合は実際に触ってみたり、専門書をあたるのが良いと思います。
また、下記のサイトにその1からまとめてきた内容を実際にコマンドで構築していく方法が記載されています。
これまでの内容で、DockerやKubeernetsのネットワークを理解し実際に構築していく上で必要な基礎知識がついたかと思います。
実際にDockerやKubernetesを起動してネットワーク設定を確認と、いろいろ理解できるようになっているはずです。